Paper : How Does BERT Answer Questions?
Github code: https://github.com/bvanaken/explain-BERT-QA
Demo : https://visbert.demo.datexis.com/
BERT reach SOTA results in a variety of Natural Language Processing tasks. In order to better understand BERT and other Transformer-based models, we will go through a layer-wise analysis of BERT’s hidden states. we examines the hidden states between encoder layers directly. Our aim is to understand how BERT works on complex downstream tasks. Question Answering (QA) is one of such tasks that require a combination of multiple simpler tasks such as Coreference Resolution and Relation Modeling to arrive at the correct answer.
There are following questions will be addressed by end of this article,
- Do Transformers answer questions decompositionally, in a similar manner to humans?
- Do specific layers in a multi-layer Transformer network solve different tasks?
- How does fine-tuning influence the network’s inner state?
- Can an evaluation of network layers help determine why and how a network failed to predict a correct answer?
For better understanding of internal workings of Transformers, will go through
- A layer-wise visualisation of token representations that reveals information about the internal state of Transformer networks. This visualisation can be used to expose wrong predictions even in earlier layers or to show which parts of the context the model considered as Supporting Facts.
- A set of general NLP Probing Tasks and extend them by the QA-specific tasks of Question Type Classification and Supporting Fact Extraction. This way we can analyse the abilities within BERT’s layers and how they are impacted by fine-tuning.
- BERT’s transformations go through similar phases, even if fine-tuned on different tasks. Information about general language properties is encoded in earlier layers and implicitly used to solve the downstream task at hand in later layers.
BERT under the Microscope
To understand which transformations the models apply to input tokens, take two approaches: First, analyse the transforming token vectors qualitatively by examining their positions in vector space. Second, probe their language abilities on QA-related tasks to examine our results quantitatively.
Analysis of Transformed Tokens
The following approach for a qualitative analysis of these transformations: Randomly select both correctly and falsely predicted samples from the test set of the respective dataset. For these samples, collect the hidden states from each layer while removing any padding. This results in the representation of each token throughout the model’s layers. The model can transform the vector space freely throughout its layers and we do not have references for semantic meanings of positions within these vector spaces. Therefore we consider distances between token vectors as indication for semantic relations.
-
Dimensionality Reduction, In order to visualize relations between tokens, apply dimensionality reduction and fit the vectors into two-dimensional space. To that end, apply T-distributed Stochastic Neighbor Embedding (t-SNE), Principal Component Analysis (PCA) and Independent Component Analysis (ICA) to vectors in each layer.
-
K-means Clustering, In order to verify that clusters in 2D space represent the actual distribution in high-dimensional vector space, apply a k-means clustering. Choose number of clusters k in regard to the number of observed clusters in PCA, which vary over layers. The resulting clusters correspond with our observations in 2D space.
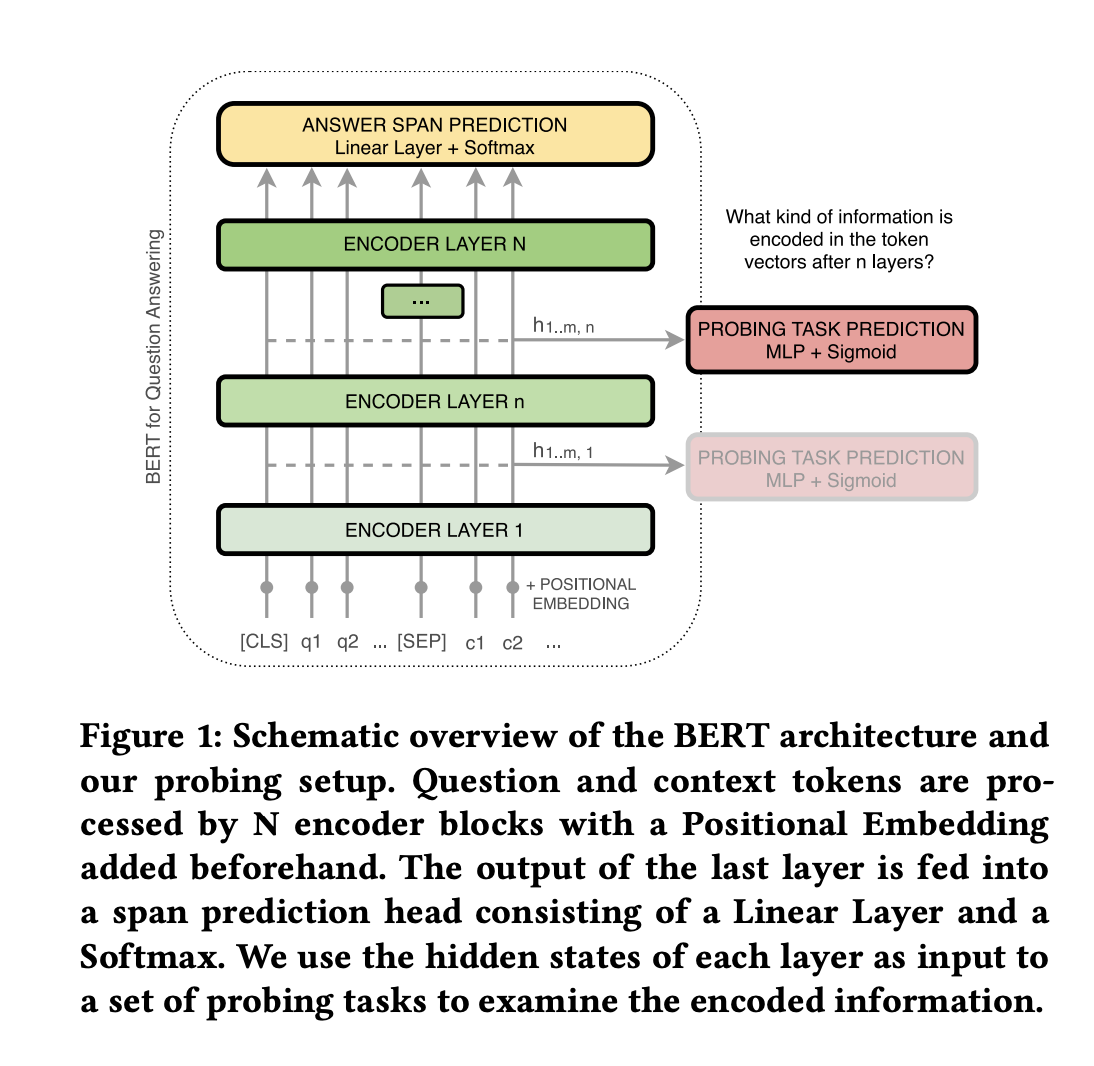
Probing BERT’s Layers
We want to know whether specific layers are reserved for specific tasks and how language information is maintained or forgotten by the model.
We use the principle of Edge Probing. Edge Probing translates core NLP tasks into classification tasks by focusing solely on their labeling part. We adopt the tasks Named Entity Labeling, Coreference Resolution and Relation Classification from the original paper as they are prerequisites for language understanding and reasoning. We add tasks of Question Type Classification and Supporting Fact Identification due to their importance for Question Answering in particular.
-
Supporting Facts - The extraction of Supporting Facts is essential for Question Answering tasks, especially in the multi-hop case. We examine what BERT’s token transformations can tell us about the mechanism behind identifying important context parts. The model has to predict whether a sentence contains supporting facts regarding a specific question or whether it is irrelevant.
-
Probing Setup - Embed input tokens for each probing task sample with our fine-tuned BERT model. Contrary to previous work, we do this for all layers (N = 12 for BERT-base and N = 24 for BERT-large), using only the output embedding from n-th layer at step n. The concept of Edge Probing defines that only tokens of “labeled edges” (e.g. tokens of two related entities for Relation Classification) within a sample are considered for classification. These tokens are first pooled for a fixed-length representation and afterwards fed into a two-layer Multi-layer Perceptron (MLP) classifier, that predicts label-wise probability scores (e.g. for each type of relation).
we take three current Question Answering datasets into account, namely SQUAD,, bAbI and HotpotQA. We intentionally choose three very different datasets to diversify the results of our analysis.

Phases of BERT’s Transformations
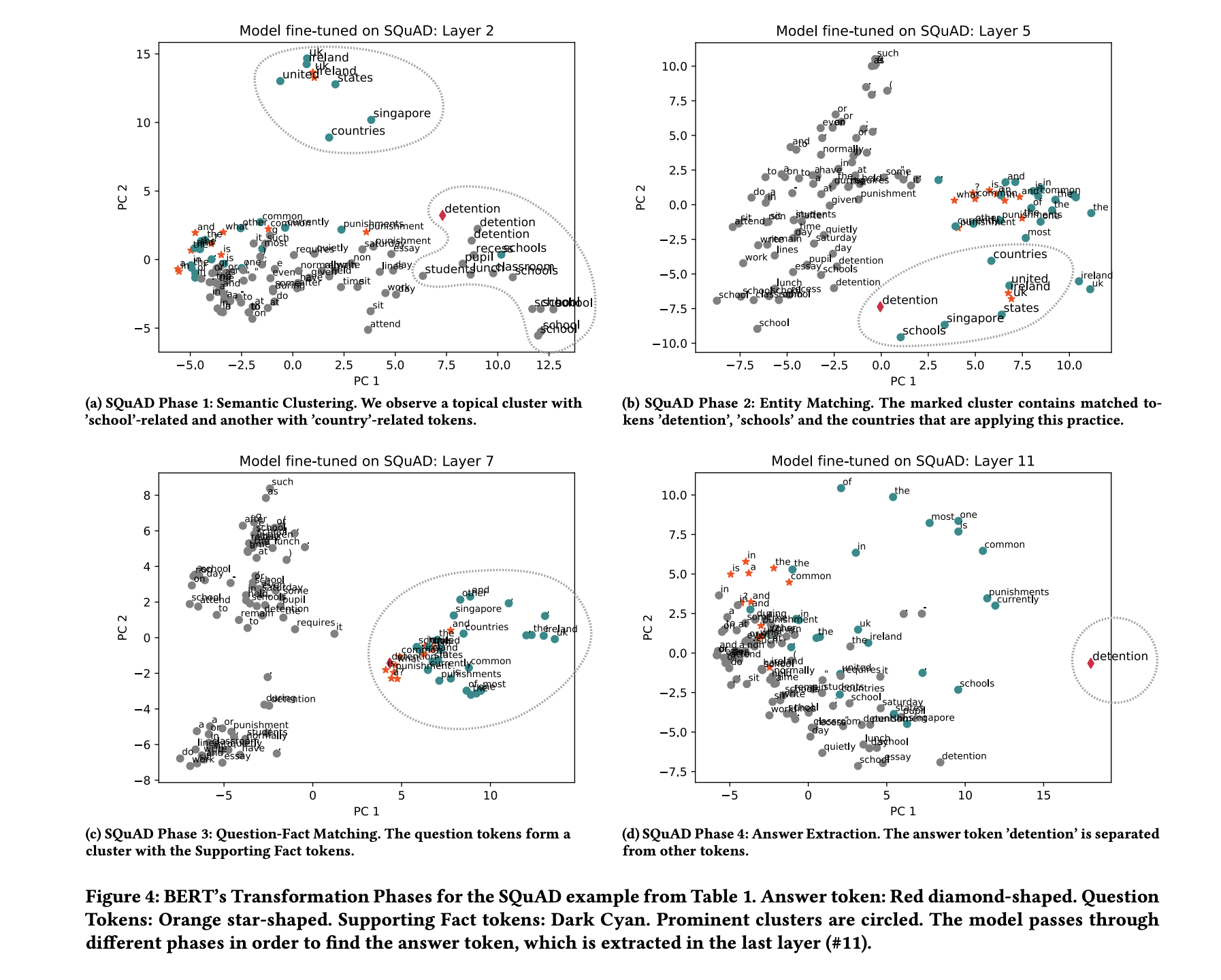
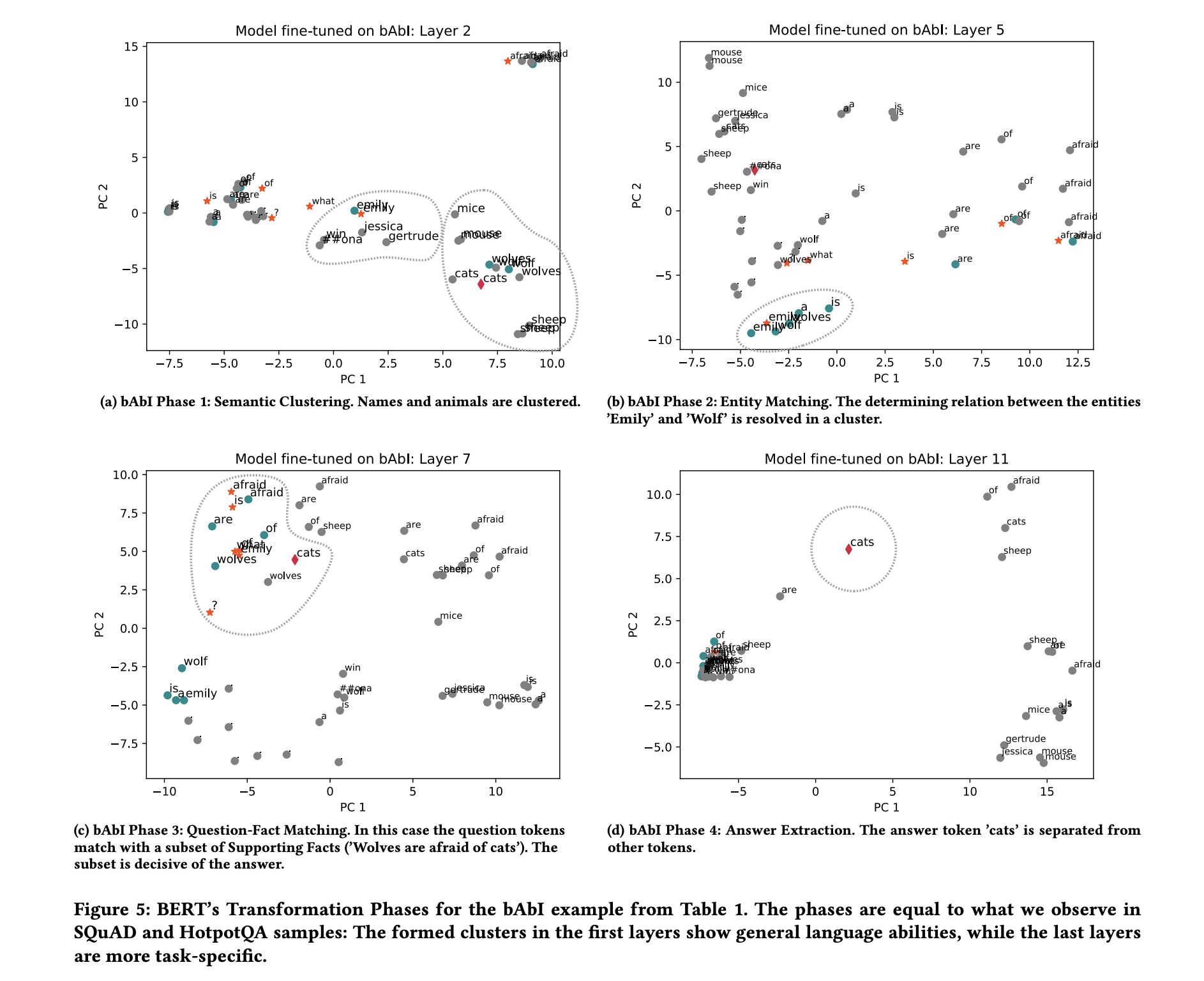
The PCA representations of tokens in different layers suggest that the model is going through multiple phases while answering a question. We observe these phases in all three selected QA tasks despite their diversity. These findings are supported by results of the applied probing tasks. We present the four phases in the following paragraphs and describe how our experimental results are linked.
- Semantic Clustering, Early layers within the BERT-based models group tokens into topical clusters. Figures 4a and 5a reveal this behaviour and show the second layer of each model. Resulting vector spaces are similar in nature to embedding spaces from e.g. Word2Vec and hold little task-specific information. Therefore, these initial layers reach low accuracy on semantic probing tasks. BERT’s early layers can be seen as an implicit replacement of embedding layers common in neural network architectures.
-
Connecting Entities with Mentions and Attributes,
-
In the middle layers of the observed networks we see clusters of entities that are less connected by their topical similarity. Rather, they are connected by their relation within a certain input context. These task-specific clusters appear to already include a filtering of question-relevant entities. Figure 4b shows a cluster with words like countries, schools, detention and country names, in which detention is a common practice in schools. This cluster helps to solve the question “What is a common punishment in the UK and Ireland?”. Another question-related cluster is shown in Figure 5b. The main challenge within this sample is to identify the two facts that Emily is a wolf and Wolves are afraid of cats. The highlighted cluster implies that Emily has been recognized as a relevant entity that holds a relation to the entity Wolf. The cluster also contains similar entity mentions e.g. the plural form Wolves. We observe analogous clusters in the HotpotQA model, which includes more cases of coreferences.
-
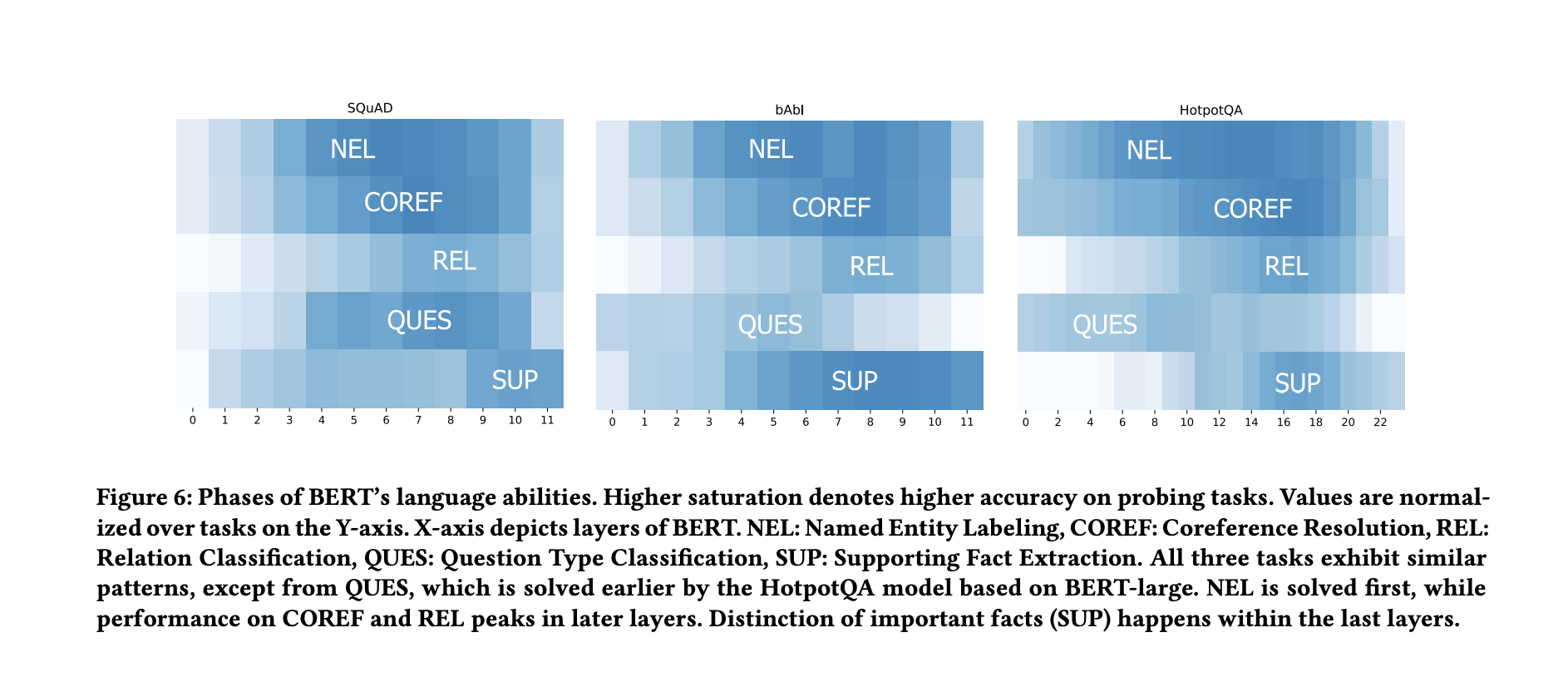
The model’s ability to recognize entities (Named Entity Labeling), to identify their mentions (Coreference Resolution) and to find relations (Relation Recognition) improves until higher network layers. Figure 6 visualizes these abilities. Information about Named Entities is learned first, whereas recognizing coreferences or relations are more difficult tasks and require input from additional layers until the model’sperformance peaks.
-
-
Matching Questions with Supporting Facts, BERT models perform a comparable step by transforming the tokens so that question tokens are matched onto relevant context tokens. Figures 4c and 5c show two examples in which the model transforms the token representation of question and Supporting Facts into the same area of the vector space.
Note - Note that the model only predicts the majority class in the first five layers and thereby reaches a decent accuracy without really solving the task.
-
Answer Extraction, In the last network layers we see that the model dissolves most of the previous clusters. Here, the model separates the correct answer tokens, and sometimes other possible candidates, from the rest of the tokens. The remaining tokens form one or multiple homogeneous clusters. The vector representation at this point is largely task-specific and learned during fine-tuning.
Analogies to Human Reasoning, (phase 1) of semantic clustering represents our basic knowledge of language and (phase 2) builds relations between parts of the context to connect information needed for answering a question. Separation of important from irrelevant information (phase 3) and grouping of potential answer candidates (phase 4). One major difference is that while humans read sequentially, BERT can see all parts of the input at once.
Additional Findings
Observation of Failure States, While for correct predictions the transformations run through the phases discussed in previous sections, for wrong predictions there exist two possibilities:
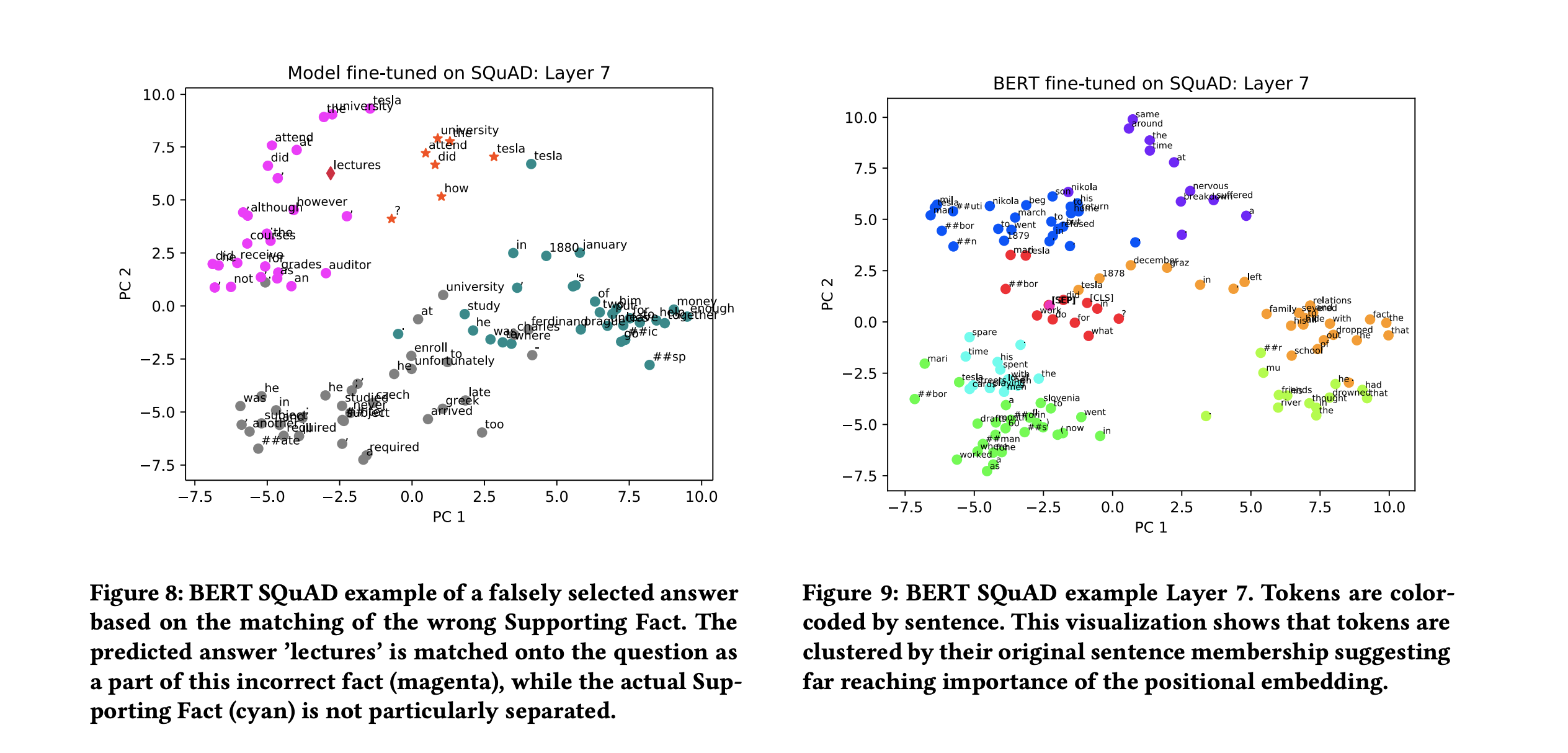
- If a candidate answer was found that the network has a reasonable amount of confidence in, the phases will look very similar to a correct prediction, but now centering on the wrong answer. Inspecting early layers in this case can give insights towards the reason why the wrong candidate was chosen, e.g. wrong Supporting Fact selected, misresolution of coreferences etc. An example of this is shown in Figure 8, where a wrong answer is based on the fact that the wrong Supporting Fact was matched with the question in early layers.
- If network confidence is low however, which is often the case when the predicted answer is far from the actual answer, the transformations do not go through the phases discussed earlier. The vector space is still transformed in each layer, but tokens are mostly kept in a single homogeneous cluster. In some cases, especially when the confidence of the network is low, the network maintains Phase (1), ’Semantic Clustering’ analogue to Word2Vec, even in later layers. An example is depicted in the supplementary material.
Impact of Fine-tuning, The pretrained model already holds sufficient information about words and their relations, which is the reason it works well in multiple downstream tasks. Fine-tuning only applies small weight changes and forces the model to forget some information in order to fit specific tasks. However, the model does not forget much of the previously learned encoding when fitting the QA task, which indicates why the Transfer Learning approach proves successful.